This note is served as a summarization of Gauss quadrature rules. There are lots of theoretical results either in the textbooks or papers. The main focus of this note, however, is to implement it with actual code from scratch. I will also try to provide some theoretical background when necessary and provide the sources where the readers can find the proofs.
1. Big Picture
In this section, I will set up a toy problem and the process to tackle it with Gauss quadrature rules. In the later sections, I will try to introduce more applications.
Goal: Our target is to estimate
using numerical approximations (assume that the function is ‘nice’).
We all know how to do this with Riemann sum:
where $-1=x_0\leq x_1 \leq \cdots \leq x_n = 1$ is a partition of the interval [-1,1], $x_i^*$’s nodes selected in between $x_i$ and $x_{i+1}$. Gauss Quadrature rules aim to do the same thing. It tries to do the approximation in the following way:
where $g(x)$ will be a modified version of $f(x)$ according to the ONP, $R[f]$ is the residual of the approximation which depends on the regularity of $f(x)$. Of course, no matter what kind of approximations we do, the errors should always depend on both the approximation rules and $f(x)$ itself. The art part of Gauss quadrature rules is to find the $w_i$ (called weight) and $x_i$ (called node) such that $R[f]$ is as small as possible.
To make this part short, I will list several key facts of Gauss Quadrature rules. Later on I will try to provide some proofs.
Key Fact:
-
Gauss Quadrature rules are indeed a class of rules. Each of them is associated with a choice of orthonormal polynomials (ONPs). For example, Gauss quadrature rule with Legendre polynomials, Gauss quadrature rule with Chebyshev polynomials of first kind, etc.
-
The nodes $x_i$ of a specific Gauss Quadrature rule are selected as either zeros or the local extrema of the associated ONPs.
-
Every ONP satisfies a three-term-recurrence-relation (3TRR), which will implicit indicate that the ONP can be defined through a special tridiagonal matrix $J$ called Jacobi matrix.
-
Given a specific ONP, the eigenvalues of the Jacobi matrix $J$ are the zeros of it. In other words, it gives the nodes $x_i$.
-
$J$ is symmetric and has eigenvalue decomposition $J = Q\Lambda Q^T$. The weights $w_i = c q_{1i}^2$, here $q_{1i}$ is the $(1,i)$th entry of matrix Q and $c$ is a constant depends on the ONP that is used.
Now we summarize the whole procedure of using Gauss Quadrature rules to approximate the integral.
Workflow:
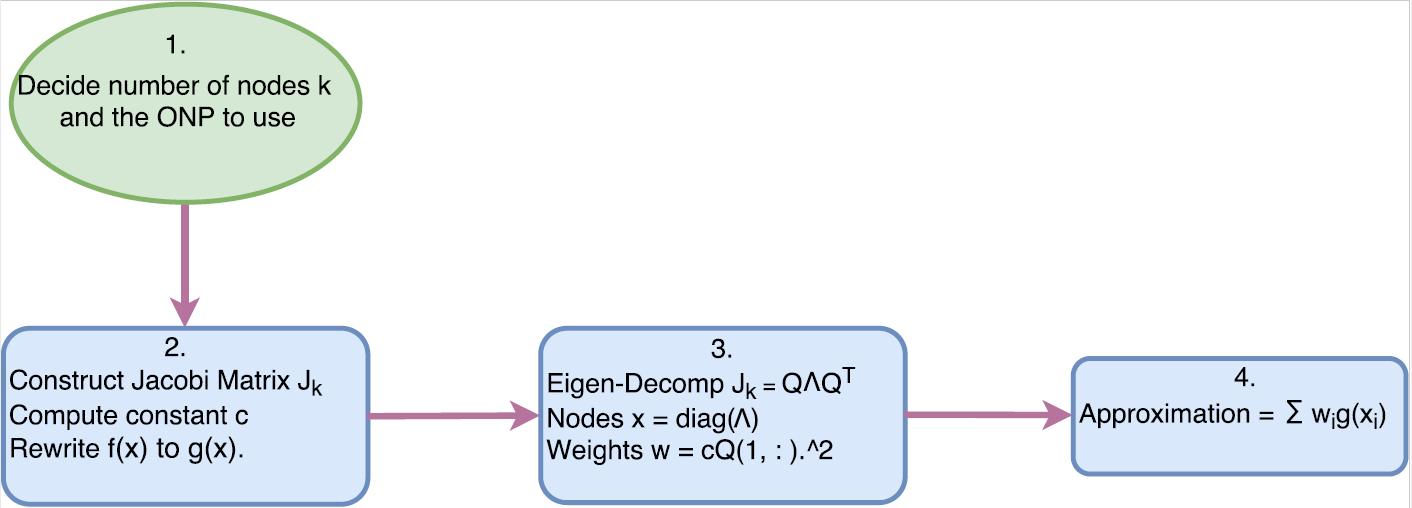
Example time!
A simple example is to calculate the Gauss Quadrature rule with Legendre polynomials. I will list some basic facts and we will discuss in details later.
Facts of Legendre polynomials:
- The Jacobi matrix of Legendre polynomial is
Here $\beta_i = \frac{1}{2\sqrt{1-(2i)^{-2}}}$. Remember that it should be a tridiagonal matrix. $k$ is number of nodes.
- The constant c for Legendre polynomial is 2.
- The function $g(x)$ is the same as $f(x)$.
A simple Matlab code demo for Gauss Quadrature rule with Legendre polynomials, see reference [1]:
function I = Quadrature_Legendre(f,n)
% n-pt Gauss quadrature of f (with Legendre polynomials)
%============== 1. Construct Jk ====================
beta = .5./sqrt(1-(2*(1:n-1)).^(-2)); % 3-term recurrence coeffs
J = diag(beta,1) + diag(beta,-1); % Jacobi matrix
% ============= 2. Eigenvalue decomposition ========
[V,D] = eig(J);
x = diag(D); [x,i] = sort(x); % nodes (= Legendre points)
w = 2*V(1,i).^2; % weights here constant c = 2.
%============== 3. Calculate the approximation.=====
I = w*f(x); % the integral from -1 to 1.
For example, to estimate $\int_{-1}^{1} x^{10} dx$ (where the true value should be 2/11), we use 6 nodes and Legendre polynomials. The Matlab code is as follows:
f = @(x) x.^10;
n = 6;
I = Quadrature_Legendre(f,n);
The output is
I =
>> 1.818181818181822e-01
The absolute error
abs(I - 2/11)
>> 3.885780586188048e-16
2. Jacobi Matrix
From the previous section, you know that the first step and also a crucial step is to figure what the Jacobi matrix is, given a specific ONP. The short answer is, for some well known ONP, such as Chebyshev polynomials (both first kind and second kind), Legendre polynomials, Laguerre polynomials, the Jacobi matrix is known.
Before my next step, let us ask a question:
Q: What exactly does it mean for polynomials to be orthogonal?
A: The inner product is 0.
We now define the inner product of polynomials. Given polynomials $p(\lambda)$ and $q(\lambda)$, the inner product (with respect to) the measure $d\alpha(\lambda)$ is defined as
For classical ONPs, the measure $d\alpha(\lambda)$ is known as well.
The following theorem may be helpful to understand where the Jacobi matrix comes from.
Theorem 1 (3TRR): For ONPs, there exists sequences of coefficients $\alpha_k$ and $\beta_k$, $k = 1,2,…$ such that (three-term-recurrence-relation)
where
and
What this theorem indicates is that the ONPs can be expressed through two sequences of numbers $(\alpha_k)$ and $(\beta_k)$ ! Suppose now I know $p_k(\lambda)$ and $p_{k-1}(\lambda)$, this theorem says, if I know two more numbers $\alpha_{k+1}$ and $\beta_k$, I will know exactly what the next polynomial should be!
The Jacobi matrix of size $n \times n$ is defined by these numbers:
Furthermore, the Jacobi matrix $J_k$ satisfies
Remark*: in many cases, the coefficients in 3TRR will help us build a matrix. However, this matrix may not necessarily be symmetric (which is required for Jacobi matrix). We then need to symmetrize the matrix. I will show this in the following examples.
Examples of 3TRR and the corresponding Jacobi matrix:
`1. Chebyshev polynomial of first kind.
The associated measure $d \alpha(\lambda) = (1-\lambda^2)^{-1/2} d\lambda$.
The zeros of this polynomial has closed form
We have,
For simplicity, I will write this as
As you can see, $T_k$ is not symmetric. Never mind, we can apply a similarity transformation such that the Jacobi matrix $J_k$ will be obtained by
Proposition 1: Given a tridiagonal matrix
If $w_i \neq 0$ and $w_i\beta_i>0$ for $i = 1,2,…,k-1$, then $T_k$ can be symmetrized by $D^{-1} T_k D$, where
The following code will symmetrize $T_k$ and thus obtain the Jacobi matrix
function [J, D] = symmetrize_T(T)
%-------------------------------------
% Symmetrize a tri-diagnoal matrix
% J = D^{-1}TD, D is a diagonal matrix
%-------------------------------------
a = diag(T);
w = diag(T,1);
b = diag(T,-1);
d = zeros(size(a));
% Calculate the diagonal entries of D
d(2:end) = cumprod(b)./cumprod(w);
d(2:end) = sqrt(d(2:end));
d(1) = 1;
D = diag(d);
Dinv = diag(1./d);
% Calculate the symmetric Jacobi matrix
J = Dinv*T*D;
`2. Chebyshev polynomial of second kind.
The associated measure $d \alpha(\lambda) = (1-\lambda^2)^{1/2} d\lambda$.
The zeros of this polynomial has closed form
We have,
In this case, the matrix is symmetric. Therefore this matrix is $J_k$.
`3. Legendre polynomials.
The associated measure $d \alpha(\lambda) = d\lambda$.
Furthermore, we have
Again, we have to symmetrize this matrix with the code mentioned before.
3. Constant c
Another question is to compute the constant c.
Indeed, the constant c can be obtained by
For example,
`1. Chebyshev polynomial of first kind.
`2. Chebyshev polynomial of second kind.
`3. Legendre polynomial.
4. Open Source Code
Indeed, there many variants of Gauss quadrature methods. Basically they assume some of the nodes are prescribed (pre-fixed).
The following MATLAB code provides Gauss quadrature rules with different polynomials and Gauss-Radau (1 pre-fixed node), Gauss-Lobatto (2 pre-fixed nodes) methods. It is designed mainly for demonstration of the ideas of Gauss Quadrature rules. Use it at your own risk.
The code can be found here.
Reference
[1] Lloyd N. Trefethen, Is Gauss Quadrature Better than Clenshaw–Curtis?.
[2] Golub & Welsch, Calculation of Gauss Quadrature Rules.
[3] Golub & Meurant, Matrices, Moments and Quadrature with Applications.