This notes is from appendix of ‘Patch Ordering as a Regularization for Inverse Problems in Image Processing’ by Gregory Vaksman etc. and is part of the book ‘numerical optimization’ by J. Wright.
Another very nice reference: OverView of Quasi-Newton Methods.
L-BFGS is a limited memory quasi-Newton method, which approximates the inverse of the Hssian matrix instead of calculating the exact one. In additional, it stores only m vectors of length n (m « n) that capture curvature information from recent iterations, instead of saving the full n × n approximation of the Hessian.
- Formulation
Let be a smooth function with .
Recall general Newton-method,
k = 0,1,2…
The classical BFGS update is the following:
where is current approximated Hessian, , .
Big Picture
To be concrete, here is the whole framework:
- Given , and
- Update x: ,
- Update step: ,
- Update gradient step: ,
- Update Hessian:
Be Practical
Well in practice, we don’t care about , instead we would like to calculate directly according to the well known Sherman-Morrison-Woodbury formula. One can verify that the inverse Hessian has the scary update:
where , , and .
Notice: In textbook ‘numerical optimization’, denotes inverse of Hessian.
How can this help us?
Manually set a number m, we can recursively update in the following way:
Ok now, let’s look at the formula above. If you are familiar with QR factorization in a recursive manner, don’t they look similar? You just recursively apply a linear operator on to initial and .
One step forward, the practical L-BFGS calculate in its iterations. Here is the recursive algorithm:
Issue: before the second loop, should initialize . ( I use the notation and to remind that they are the inversion of Hessian.) Also pay attention that the here is the inverse Hessian!

Does this work?
Let’s work on the first loop: one can show that for each ,
And by definition, . So what the first loop really does is to calculate
and
(for the latter, notice that when , .
Now check the second loop, for each ,
Let’s run for the next iteration, we will get
Another comment here is that , so if we keep moving on, we will get the final update !! ( I use the notation and to remind that they are the inversion of Hessian.)
Finally, the whole algorithm
Recall the condition of line search, we also call it Wolfe condition: 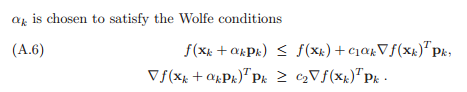
Then the following is the whole L-BFGS algorithm: 
Final Remark Is it really helpful than BFGS?
The following is from the reference OverView of Quasi-Newton Methods:
Note that this process requires only storing and for or floating-point values, which may represent drastic savings over values to store . After each iteration, we can discard the vectors from iteration , and add new vectors for iteration . Also note that the time required to compute is only .